
One of the trickier tasks a Maximo administrator will run into is migrating information from a legacy system into Maximo. And one of the trickiest migrations can be importing long text notes from a legacy system into Maximo's Long Description fields. When I have to migrate information into Maximo, understanding the source information is critical. Straight plain text will use hidden characters to do things like indent a line with a Tab or move the cursor to a new line with the Enter key. For text migrations, the focus is how does the legacy text handle character codes for carriage return and new line feed.
A couple of assumptions going forward: 1) that your Maximo environment is using Rich Text for Long Descriptions 2) that you're migrating information from a Microsoft based environment. If these don't apply, adjust as needed.
A Little Background First
The first step is making sure Maximo's External System being used to import the legacy text1 is set up to use Long Descriptions. IBM has a quick tech note on "Including long descriptions in the MIF". Review the Enterprise Service you'll be using in the External System to verify it's setup to use Long Descriptions.
The key point to remember going forward is the goal is not to migrate the legacy text character for character, but to migrate plain text into rich text. As prefaced earlier, the key is to understand how your legacy system interprets some key character. For most Microsoft based systems, hitting the Enter2 key on your keyboard puts your cursor at the beginning of the next line. Under the hood, getting that same functionality in text fields on SQL text requires the insertion of two hidden characters into your text document: char(13) and char(10).
Since those byte characters don't show up in Rich text, doing a direct migration of SQL text into a Long description will look like this:
SQL Text:
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Phasellus maximus nulla ut lectus dictum tristique.
Nam a faucibus odio. Aliquam erat volutpat.
Maximo Long Description:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus maximus nulla ut lectus dictum tristique. Nam a faucibus odio.
Why?
There are 2 primary reasons:3
- When I extract the text from the SQL database, the typical path to extract and manipulate the text will strip the
char(13)andchar(10)characters. - Rich text doesn't recognize those characters, rich text recognizes tags within the text.
So to get plain text to migrate to rich text, I have to covert the char(13) and char(10) characters into something recognizable by Maximo's rich text engine.
Maximo Rich Text Tagging
If I go into Maximo and enter parts of the Lorem Ipsum sentences into a long description field, it will look like this in the UI:
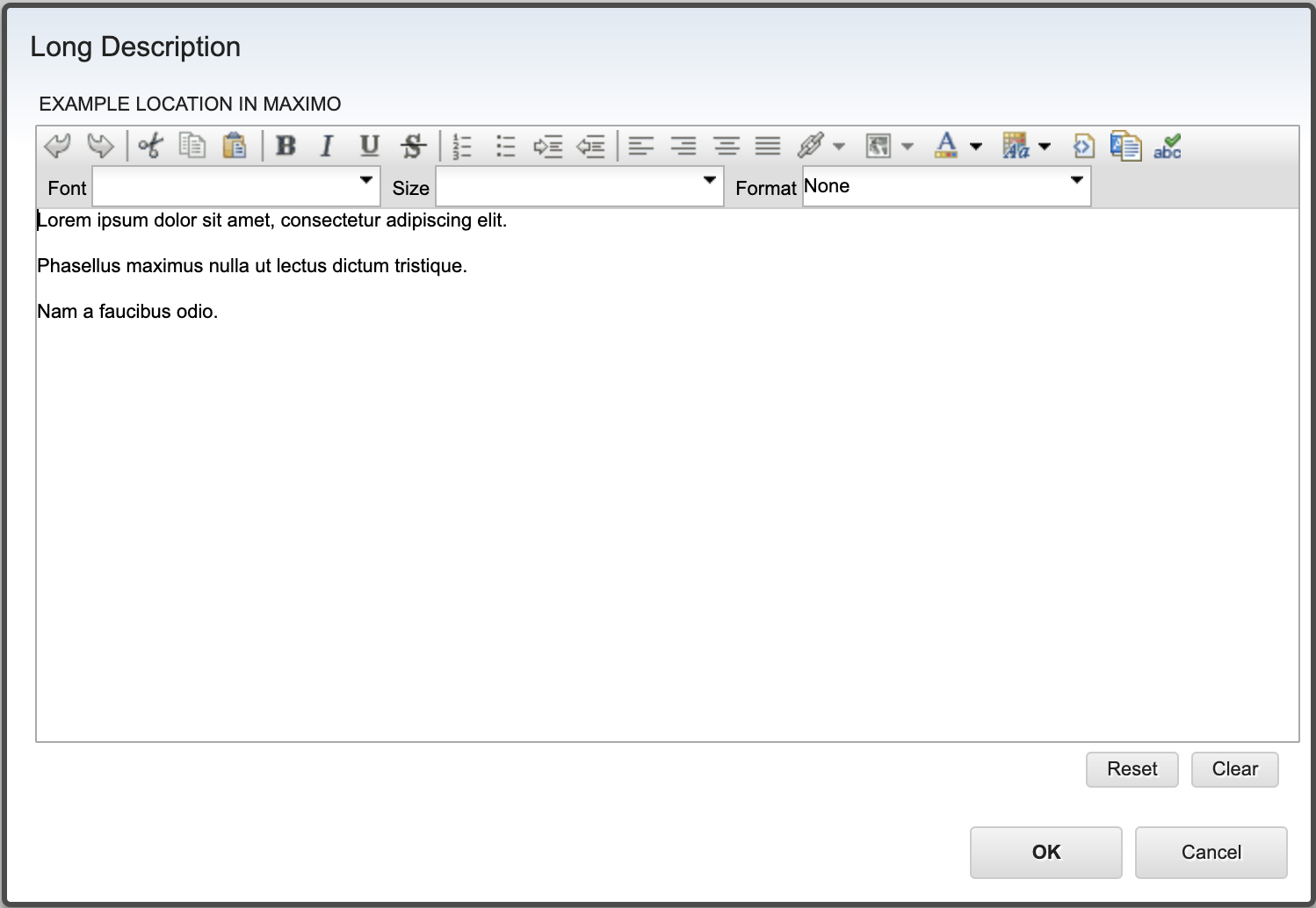
Looking at this same Long Description at the database level shows:
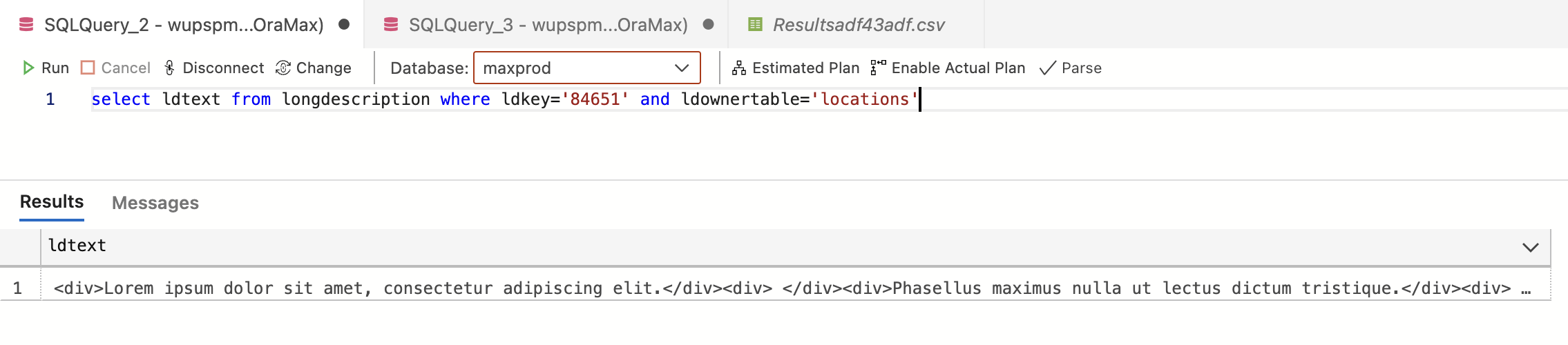
So now I can see how Maximo will interpret a carriage return into rich text by using <div> tags. The problem is applying wrapping tags on text is more work than I normally want to take on.4 Since the default by Maximo is to use a double <div> tags for a carriage return, I can use the equivalent of <br /> to do the same. If I update the long description field from:
<div>Lorem ipsum dolor sit amet, consectetur adipiscing elit.</div><div> </div><div>Phasellus maximus nulla ut lectus dictum tristique.</div><div> </div><div>Nam a faucibus odio.</div><!-- RICH TEXT -->
and switch the text string to:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. <br /><br />Phasellus maximus nulla ut lectus dictum tristique. <br /><br />Nam a faucibus odio.
The UI view when using the <br /> tags results in the same visual output.
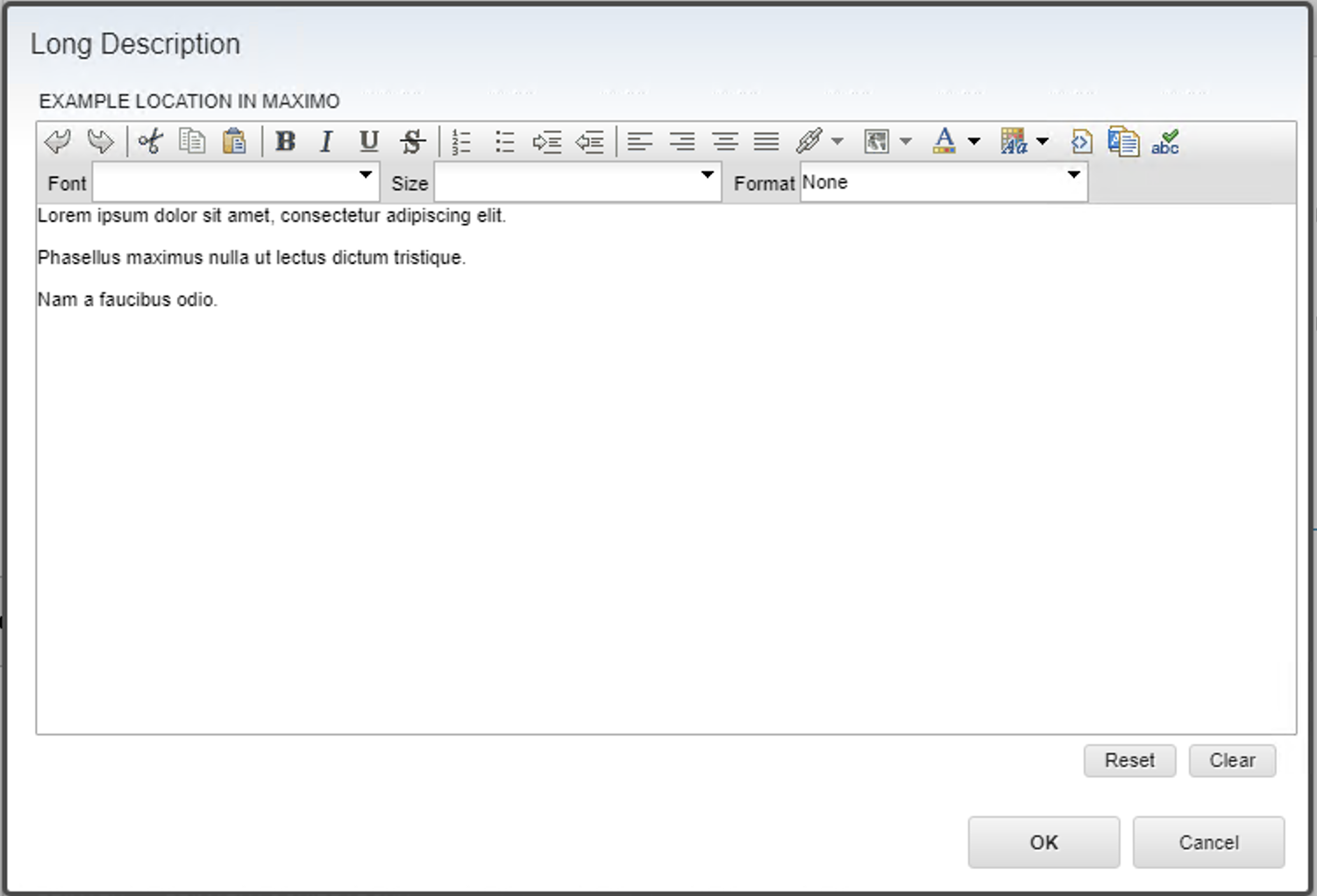
Since we get the same results, the use of <br /> tags for the text transformation is simpler.
SQL Replacement for Extract
Knowing that SQL will use two different byte characters to insert a carriage return in the legacy text field, I can use that information to create a script to shift the byte characters into rich text tags. Looking at the legacy text at the byte level, I can replace the characters in the output by using a double REPLACE statement.
select KEYFIELD, REPLACE (REPLACE (cast(LEGACYTEXT as nvarchar(max)), CHAR(13), '<br />'), CHAR(10), '') as LEGRACY_TEXT from LEGACYTABLE;
The first REPLACE statement CHAR(13), '<br />' will transform the hidden CHAR(13) byte character insert a <br /> tag into the text. The other REPLACE will take the CHAR(10) byte code and leave a blank entry into the migrated text.
Now all the text I need to extract and migrate will be properly tagged for import as rich text into a Long Description field. Since the legacy text is encoded with the tags, using a plain text External System, like CSVDATA, all the legacy text will import properly.